정의 : 정규화된 엔티티, 속성, 관계에 대해 성능 향상을 목적으로 중복, 통합, 분리를 수행하는 데이터 모델링 기법
특징 : 테이블, 칼럼, 관계의 반정규화를 종합적으로 고려(일반적으로 속성의 중복 시도)
과도한 반정규화는 데이터의 무결성을 침해
반정규화 기법 1) 테이블 반정규화 - 테이블 병합 : 관계 병합, 슈퍼/서브타입 병합 (one to one, plus, single type) - 테이블 분할 : 수직, 수평 분할 - 테이블 추가 : 중복 테이블 / 통계 테이블 / 이력 테이블 / 부분 테이블 추가
2) 칼럼반정규화 - 중복칼럼 추가 : 조인 횟수를 감소시키기 위해 다른 테이블의 칼럼 중복 칼럼 저장⭐ - 파생칼럼 추가 : 값의 계산으로 인한 성능 저하 예방, 예상값을 미리 계산해서 중복 칼럼 저장 (Derived 칼럼)⭐ - 이력테이블 칼럼 추가 : 기능성 칼럼, 대량 이력 데이터 처리의 성능 향상을 위해 종료 여부, 최근값 여부 등의 칼럼 추가로 저장 - PK의 의미적 분리를 위한 칼럼 추가 : PK가 복합 의미를 갖는 경우 단일 속성을 구성시 발생, 구성 요소 값의 조회 성능 향상을 위해 일반 속성을 추가 - 데이터 복구를 위한 칼럼 추가 : 사용자의 실수 또는 응용프로그램 오류로 인해 데이터가 잘못 처리된 경우 원래 값으로 복구 위해 이전 데이터를 임시로 중복 저장
3)관계반정규화 - 중복관계 추가 : 조인으로 정보 조회가 가능 but 조인 경로 단축을 위해 중복관계 추가 * 테이블과 칼럼의 반정규화는 데이터 무결성에 영향을 미침 * 관계의 반정규화는 데이터 무결성 보장 가능, 데이터처리 성능 향상
1. 성능 저하 원인 · 하나의 테이블에 데이터 대량집중 : 테이블 구조 너무 커져 효율성 ↓, 디스크 I/O ↑ · 하나의 테이블에 여러 개의 컬럼 존재 : 디스크 점유량↑, 데이터 읽는 I/O량 ↑ · 대량의 데이터가 처리되는 테이블 : SQL 문장에서 데이터 처리 위한 I/O량 ↑, 인덱스 구성 · 대량의 데이터가 하나의 테이블에 존재 : 인덱스의 크기 ↑ 성능 저하 · 컬럼이 많아지는 경우 : 로우 체이닝, 로우 마이그레이션 발생
2. 해결 방안 - 한 테이블에 많은 칼럼 → 수직분할 - 대량 데이터 저장 문제 → 파티셔닝, PK에 의한 테이블을 분할 * 대량 데이터 발생에 따른 테이블 분할 - 수직분할 : 컬럼 단위로 분할하여 I/O 경감 - 수평분할 : 로우 단위로 분할하여 I/O 경감
3. 대량 데이터 발생으로 인한 현상 · 블록: 테이블의 데이터 저장 단위 · 블록 I/O 횟수 증가, 디스크 I/O 가능성 상승, 디스크 I/O 성능 저하 - 로우 체이닝 (Row Chaining) : 행(Row) 길이가 길어 데이터 블록 하나에 데이터를 모두 저장하지 않고 두 개 이상의 블록에 걸쳐 하나의 로우를 저장하는 형태 - 로우 마이그레이션 (Row Migration) : 수정된 데이터가 해당 블록에 저장하지 못하고 다른 블록의 빈 공간에 저장되는 현상
4. 파티셔닝 (Partitioning) - 테이블 수평 분할 기법, 논리적으로는 하나의 테이블이지만 물리적으로 여러 데이터 파일에 분산 저장, 데이터 조회 범위를 줄여 성능 향상 - Range Partition : 범위로 분할 (고객번호 1~1000, 1001~2000 등) - List Partition : 특정한 값을 기준으로 분할 (지역 : 서울, 부산 등) - Hash Partition : 해시 함수를 적용하여 분할, 데이터 위치 알 수 없음 * 해시 함수 : 임의 길이의 데이터를 짧은 길이의 데이터로 매핑하는 함수 - Composite Partition : 여러 파티션 기법을 복합적으로 사용하여 분할
1. 슈퍼/서브타입 데이터 모델 - 논리적 데이터 모델에서 주로 이용 (분석단계에서 많이 쓰임) - 물리적 데이터 모델로 설계 시 문제 발생 (적당한 노하우 X → 1:1 또는 All in one 타입이 되어버려 성능 저하) - 슈퍼타입 : 공통부분을 슈퍼타입으로 모델링 - 서브타입 : 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성만 모델링
2. 데이터베이스 성능 저하 원인 3가지 ① Union 연산에 의해 성능 저하 - 트랜잭션 : 전체를 일괄처리, 테이블 : 개별로 유지 ② 조인에 의해 성능 저하 - 트랜잭션 : 슈퍼+서브타입 공통 처리, 테이블 : 개별로 유지 ③ 불필요하게 많은 데이터 집적 - 트랜잭션 : 서브타입만 개별로 처리, 테이블 : 하나로 통합
3. 슈퍼/서브타입 데이터 모델 변환을 통한 성능 향상 - 변환기준 : 데이터 양, 트랜잭션 유형 - 데이터 소량 : 데이터 처리 유연성 고려하여 가급적 1:1 관계 유지 - 데이터 대량 : 3가지 변환 방법 (개별 테이블, 슈퍼+서브타입 테이블, 하나의 테이블) ① 1:1 타입 (One to one type) : 개별로 처리하는 트랜잭션에 대해 개별 테이블 구성하여 1:1 관계 가짐 ② 슈퍼/서브 타입 (Plus type) : 슈퍼+서브 공통으로 처리하는 트랜잭션에 대해 슈퍼/서브 각각 테이블 구성 ③ All in One 타입 (Single type) : 전체를 하나로 묶어 트랜잭션이 발생, 단일 테이블 구성
⇨ 쪼개질수록 확장성↑/ Disk, I/O 성능↑/ 조인 성능↓/ 관리 용이성↓
4. PK/FK 칼럼 순서 및 성능 - 일반적인 프로젝트에선 PK/FK 칼럼 순서의 중요성을 인지하지 못해 데이터 모델링 되어있는 상태로 DDL을 생성하여 성능이 저하되는 경우가 빈번 ① 인덱스 중요성 : 데이터 조작 시 가장 효과적으로 처리될 수 있는 접근 경로 제공 * 인덱스의 특징 : 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때, 앞쪽에 위치한 속성의 값이 비교자로 있어야 인덱스가 좋은 효율을 나타낼 수 있다. 앞쪽에 위치한 속성값이 가급적 ‘=’ 아니면 최소한의 범위인 ‘BETWEEN'이 들어와야 됨 ② PK/FK 설계 중요성 : 데이터 접근 시 접근경로 제공, 설계단계 마지막에 칼럼 순서 조정 ③ PK 순서의 중요성 : 물리적 모델링 단계에서 스스로 생성된 PK 외에 상속되는 PK 순서도 중요 ④ FK 순서의 중요성 : 조인을 할 수 있는 수단이 됨(=경로), 조회 조건 고려해서 반드시 인덱스 생성
5. PK 순서를 조정하지 않으면 성능 저하 되는 이유✳️✴️ - 조회 조건(WHERE)에 따라 인덱스를 처리하는 범위가 달라짐 - PK의 순서를 인덱스 특징에 맞게 생성하지 않고 자동으로 생성하면, 테이블에 접근하는 트랜잭션이 인덱스 범위를 넓게 하거나 풀 스캔(full scan)을 유발
6. 물리적 테이블에 FK 제약이 걸려있지 않은 경우 인덱스 미생성으로 생긴 성능 저하 - 물리적으로 두 테이블 사이 FK 참조 무결성 관계를 걸어 상속받은 FK에 인덱스 생성
7. 인덱스 엑세스 범위 좁히는 가장 좋은 방법✳️✴️ - PK가 여러 개일 때, Where절에 사용하는 조건용 칼럼들이 우선순위가 되어야 함 - ‘=’, EQUAL 조건, 동등 조건에 있는 칼럼이 제일 앞으로 - BETWEEN, IN 범위 조건에 있는 칼럼이 그다음 순위 - 나머지 PK는 그 뒤에 아무렇게
1. 분산 데이터베이스의 개념 - 물리적으로 분산된 데이터베이스를 하나의 논리적 시스템으로 사용 - 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역에서 노드로 위치시켜 사용성과 성능을 극대화하는 데이터베이스
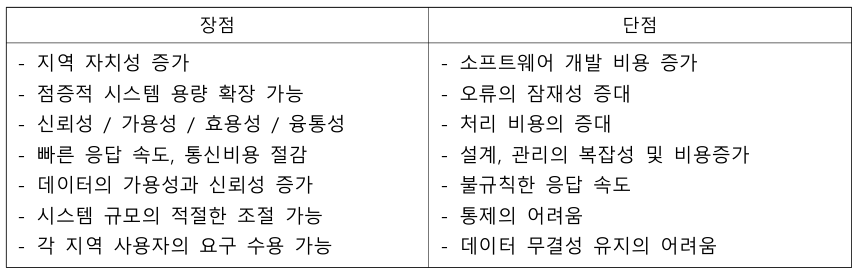
2. 분산 데이터베이스 설계 방식 - 상향식 : 지역 스키마 작성 후 전역 스키마 작성 - 하향식 : 전역 스키마 작성 후 지역사상 스키마 작성 3. 분산 데이터베이스의 장/단점
분산 데이터베이스의 장/단점
4. 분산 DB의 투명성 - 분할 투명성 : 하나의 논리적 관계가 분할되어 각 단편의 사본이 여러 사이트에 저장 - 위치 투명성 : 사용하려는 데이터 저장 장소가 명시되지 않아도 됨 - 지역사상 투명성 : 지역 DBMS와 물리적 DB 사이의 사상이 보장됨 - 중복 투명성 : DB 객체 중복 여부를 몰라도 됨 - 장애 투명성 : 구성 요소(DBMS, 컴퓨터)의 장애에 무관하게 트랜잭션의 원자성이 유지됨 - 병행 투명성 : 다수의 트랜잭션을 동시 수행했을 때 결과의 일관성이 유지됨 5. 분산 데이터베이스의 적용 기법 ① 테이블 위치 분산 : 설계된 테이블의 위치를 분산 - 테이블 구조 변경 X - 테이블이 다른 데이터베이스에 중복으로 생성 X - 정보를 이용하는 형태가 각 위치별로 차이가 있을 경우 사용 - 테이블 위치를 파악할 수 있는 도식화된 위치별 데이터베이스 문서 필요 ② 테이블 분할 분산 (수평, 수직분할) : 테이블을 수평이나 수직으로 분할하여 분산 - 수평 분할 : 특정 칼럼의 값 기준으로 로우 단위 분리, 칼럼 분리 X - 수직 분할 : 칼럼을 기준으로 칼럼 단위로 분리, 로우 분리 X ③ 테이블 복제 분산 (부분, 광역복제) - 동일한 테이블을 다른 지역이나 서버에서 동시 생성, 원격지 조인을 내부조인으로 변경하여 성능 향상. 프로젝트에서 많이 사용되는 데이터베이스 분산 기법 * 부분복제 - 마스터 데이터베이스에서 테이블의 일부 내용만 다른 지역이나 서버에 위치 - 본사는 통합 테이블 관리, 각 지사에서는 지사에 해당하는 로우만 관리 - 실제로는 지사에서 먼저 데이터 발생 → 본사에서 전체 통합 * 광역복제 - 통합된 테이블을 본사에 가지고 있으며 각 지사에 본사와 동일한 데이터 분배 - 동일한 테이블을 여러 곳에 복제하여 관리 - 본사에서 데이터의 입력, 수정, 삭제 발생 → 지사에서 이를 반영 ④ 테이블 요약 분산 (분석, 통합요약) - 유사한 내용의 데이터를 서로 다른 관점/수준에서 요약하여 분산 관리 * 분석요약 (rollup replication) - 각 지사별 동일한 주제의 정보를 본사에서 통합하여 전체 요약 정보 산출 * 통합요약 (consolidation replication) - 각 지사별로 존재하는 다른 내용 정보를 본사에 통합, 다시 전체의 요약 산출